算法小结
数据结构
链表
虚拟节点
链表设置虚拟头结点dummyhead,这样对链表来说,第一个元素就是dummyhead的next所对应的节点元素,而不是dummyhead所对应的节点元素。
dummyhead位置所对应的元素是根本不存在的,这只是未来我们编写逻辑方便而出现的一个虚拟头结点。
dummyhead就是索引为0的这个位置的元素的前一个节点。当我们有了dummyhead后,为链表添加一个元素,就不需要对头结点进行特殊处理了,只需要找到等待添加位置的前一个位置的节点,
此时对于链表来说,所有位置都有前一个节点。
反转法
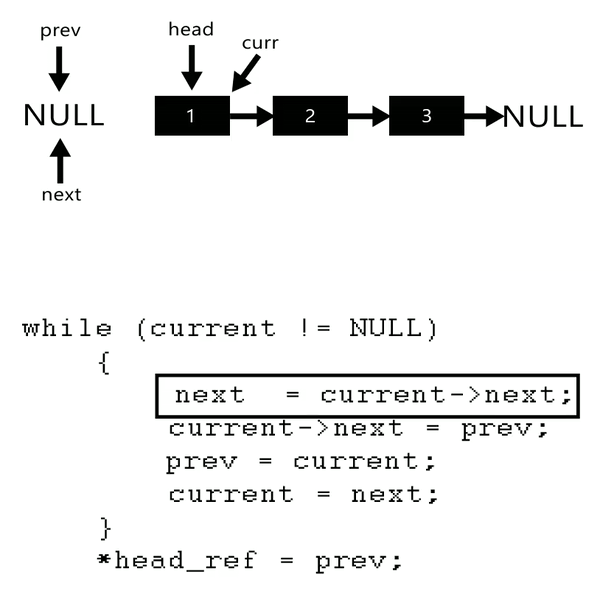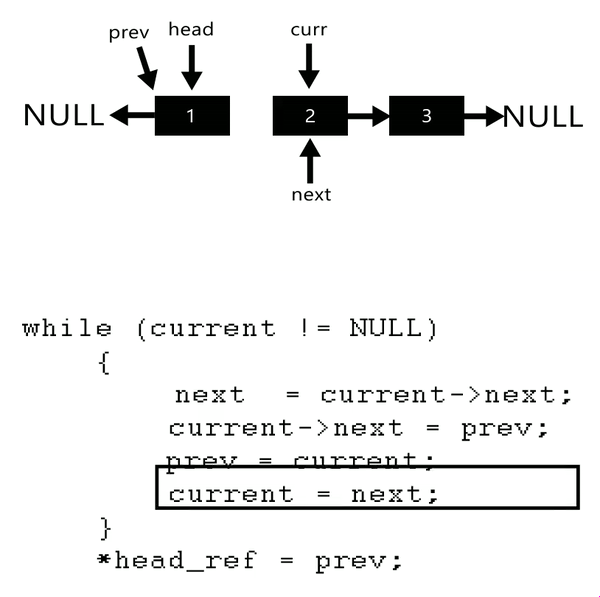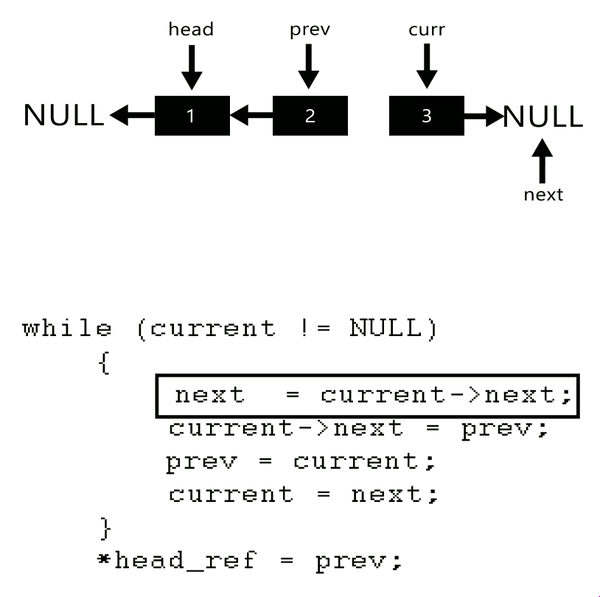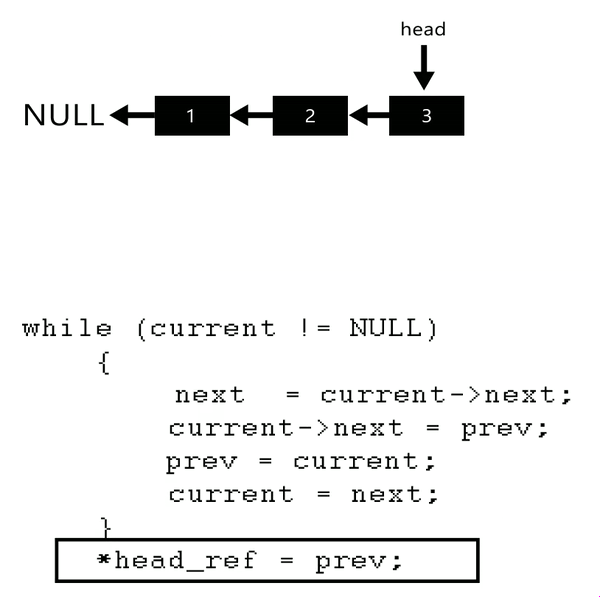
反转的方法很简单:切出一个要反转的头节点,next置为null,作为尾节点的开始.然后不停的将头结点放入尾节点之前.
头插法
这种方法类似于麻将洗牌,可以将自己的手牌当做链表,反转动作可以认为,我们要将手牌中的一张牌插入前面的牌的位置当中.
1.拿出这张牌
2.此时缺了空位,待插入位置整体向后移动链接空位之后的牌,腾出待插入的位置.
3.插入的牌链接空位之后的牌
4.头牌链接插入的牌
图片以反转链表II的拿过来,真正的翻转链表需要g是指向dummynode.
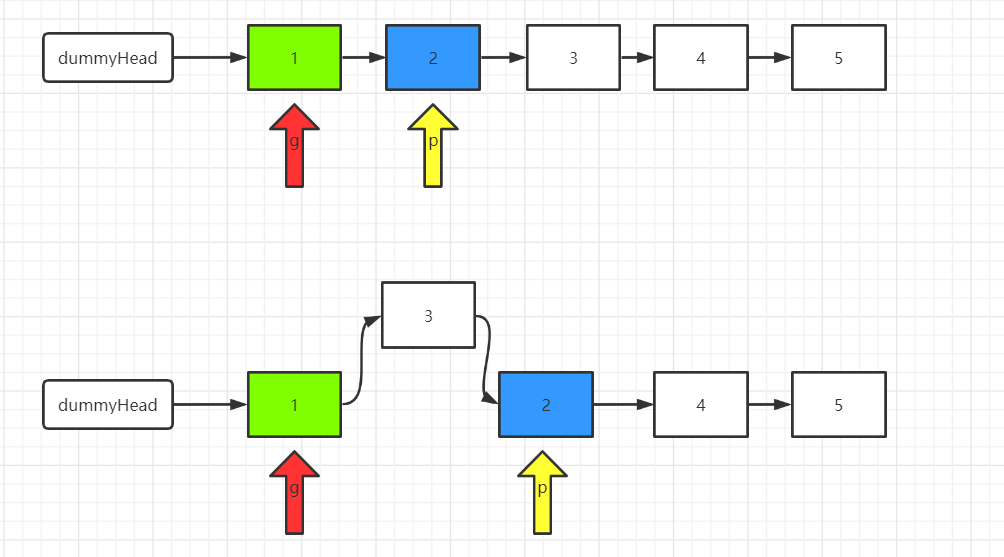
首先要构建一个dumynode,然后以插牌的方式进行构建.g不会动只有p在动,这与上述的反转法,是有区别的.
1 | while(p.next != nil) { |
树
广度遍历
1.非递归用,双向链表或者队列实现.
1 | printLevelorder(tree) |
2.递归很简单,按层级遍历,但是要注意以下发放效率很差,远不如非递归的实现,方法需要改进.
1 | /*Function to print level order traversal of tree*/ |
深度遍历
递归版本很简单,非递归的版本.
1.后续遍历,双栈实现.
1.前序遍历,单栈实现.
栈
入栈的元素可以是数组的下标或者是元素.或者可以设计一种KV的数据结构保存入栈的元素.
涉及到距离的题目一般需要存储下标位置.
单调栈-递减栈
站内元素是顺序的,栈顶到栈底整体由小到大.
单调栈-递增栈
站内元素是顺序的,栈顶到栈底整体由大到小.
Hash
hash结构是一种比较特殊的数据结构,key-value映射的数据结构.一般碰撞发生后语言底层会进行处理.
前缀和
区间的问题几个思路供参考:1、滑动窗口(双指针) 2、前缀和的差 3、线段树(树状数组)
前缀和的差值计算,就涉及到前缀计算结果的存储那么就需要用到hash表结构进行存储.
操作
双指针
涉及到数组有序的首先要想到的是双指针能不能实现
一般的双指针根据运动方向分成两种:
1.指针一起从左到右移动(前缀和,滑动窗口上面也有介绍)
2.指针从两边向中间移动(二分,交换元素等)
根据移动的速度
可以分为快慢指针,一般快指针运动速度是慢指针的两倍.快慢指针一般在连表当中很常见.
二分
二分是一种重要的思路,无论是在有序或者无序的输入中查找都能用到.
最重要的判断使用二分的方法是:能否将输入元素分成两部分,其中结果只应出现在其中的一部分,递归下去就可以得到结果.
二分法要注意起始的边界,关建点是起始边的界定义,也就是你要二分查找的范围.
二分在二维有序数据的处理本质上是分两拨,在二维数据集里进行分拨查找.
这些概念有点抽象只能自己慢慢体会.
二分模板
1 | int binarySearch(int[] nums, int target) { |
为什么while里写的是 <=, int类型的除法需要注意的是只会向下取整,比如[left => 0,right => 1].这样会导致问题的发生.mid=0检查完后,left=1 如果while语句写的是小于,那么会引起问题的产生, right节点就不会检查到了. <= 是确保left与right指针能够相遇,
最主要还是要理解搜索区间的概念,如果按照while <的条件那么有些情况是需要注意的,根据指针移动的规律上下条件有三种::
注意 left= 0, right = len(nums)
mid = ( right + left ) /2
- 确定下边界
1 | while left<right: |
- 确定上边界
1 | while left<right: |
数学
模
同余定理
给定一个正整数m,如果两个整数a和b满足a-b能够被m整除,即(a-b)/m得到一个整数,那么就称整数a与b对模m同余,记作a≡b(mod m)。
也就是说(a-b)%m == 0 那么就等价于 a%m == b%m.
这在我们处理涉及到余数相关的问题有着巨大的帮助.
动态规划
试用条件
-
最优化原理:
最优化原理可这样阐述:一个最优化策略具有这样的性质,不论过去状态和决策如何,对前面的决策所形成的状态而言,余下的诸决策必须构成最优策略。简而言之,一个最优化策略的子策略总是最优的。一个问题满足最优化原理又称其具有最优子结构性质 -
无后效性
将各阶段按照一定的次序排列好之后,对于某个给定的阶段状态,它以前各阶段的状态无法直接影响它未来的决策,而只能通过当前的这个状态。换句话说,每个状态都是过去历史的一个完整总结。这就是无后向性,又称为无后效性。 -
子问题重叠
动态规划算法的关键在于解决冗余,这是动态规划算法的根本目的。动态规划实质上是一种以空间换时间的技术,它在实现的过程中,不得不存储产生过程中的各种状态,所以它的空间复杂度要大于其他的算法。选择动态规划算法是因为动态规划算法在空间上可以承受,而搜索算法在时间上却无法承受,所以我们舍空间而取时间。
解题方法
暴力的递归解法 -> 带备忘录的递归解法 -> 迭代的动态规划解法。
找到状态和选择 -> 明确 dp 数组/函数的定义 -> 寻找状态之间的关系。
组合问题划分
组合问题公式
dp[i] += dp[i-num]
True、False问题公式
dp[i] = dp[i] or dp[i-num]
最大最小问题公式
dp[i] = min(dp[i], dp[i-num]+1)或者dp[i] = max(dp[i], dp[i-num]+1)。
背包问题
背包问题的关注点在于,背包容积的关系,由前一个背包容积推导到下一个背包的容积的问题.
注意背包相关问题的典型就是参数是一个整型用于构建动态规划的二维表.
背包问题具备的特征:给定一个target,target可以是数字也可以是字符串,再给定一个数组nums,nums中装的可能是数字,也可能是字符串,问:能否使用nums中的元素做各种排列组合得到target。
一般思考的思路
-
递归求解:由于有大量重复子问题,因此必须使用缓存,以避免相同问题重复求解,这个方法叫记忆化搜索,在《算法导论》这本书上也把它归入到动态规划的定义中。这种思考问题的方式是从上到下的,直接面对问题求解,遇到什么问题,就解决什么问题,同时记住结果;
-
动态规划告诉了我们另一种思考问题的方式:从底向上,可以不直接面对问题求解,从这个问题最小的样子开始,通过逐步递推,至到得到所求的问题的答案。
0-1 背包问题
如果是0-1背包,即数组中的元素不可重复使用,nums放在外循环,target在内循环,且内循环倒序;
倒序是为了解决覆盖的问题,不能先求j - nums[i],那么这样的话j-nums[i]已经放入了nums[i],在之后的求解中会重复利用该元素求解结果,导致结果错误。
1 | for i := 1; i < len(nums); i++ |
完全背包问题
如果是完全背包,即数组中的元素可重复使用,nums放在外循环,target在内循环。且内循环正序。
正序是因为本次循环要利用上个原素的信息,物品是重复可以使用的。
1 | for i := 1; i < len(nums) |
顺序问题
如果组合问题需考虑元素之间的顺序,那应该当成排列问题,需将target放在外循环,将nums放在内循环。
原因:
在不考虑物品排列的情况下,我们通常先遍历物品,再遍历背包容量。这是因为对于每个物品,我们都需要在其不放入背包和放入背包两种情况下做选择,而这个选择依赖于背包的剩余容量。所以我们需要先确定物品,再确定背包容量。
在考虑物品排列的情况下,我们通常先遍历背包容量,再遍历物品。这是因为每个物品可以被多次选择,所以我们需要在每种背包容量下,考虑所有的物品。所以我们需要先确定背包容量,再确定物品。

1 | for i := 1; i <= target; i++ |
1 | recsum(5) |
尾递归:
1 | function tailrecsum(x, running_total = 0) { |
1 | tailrecsum(5, 0) |