本文主要讲述查询相关的使用,不再对ES的基础概念做赘述.
倒排索引 正排索引:构建文档ID与单词的关联关系
MySQL支持倒排索引,但是5.6之前的版本只支持拉丁字符,对汉字等不支持.因此作为搜索引擎具有很大的局限性.
ES实现
单词词典:记录所有文档的单词,记录单词与倒排关联表的关联关系
倒排列表:记录的单词对应的文档结合,由倒排索引组项成
倒排索引项:
文档ID
词频TF,该单词在文档中出现的次数
位置,单词在文档中分词的位置
偏移,记录单词开始结束的位置,实现高亮显示
可以在ES当中对字段不设置索引
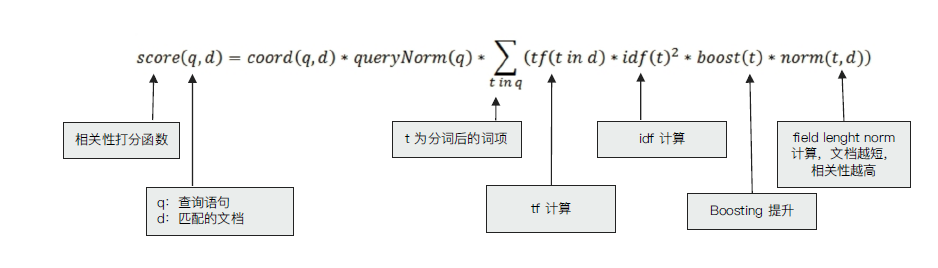
相关性与相关性算分 搜索的相关性算分,描述了一个文档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果进行算分_score.
词频 Term Frequency:检索词在一篇文档中出现的频率, 检索词出现的次数除以文档的总字数
Stop Word:“的” 在上诉文档中出现了很多次,但是对贡献相关度几乎没有用处,不应该考虑他们的TF
逆文档频率 TF:检索词在所有文档中出现的频率
TF-IDF算法 TF-IDF:本质上是TF*IDF(权重)求和
Lucene中的TD-IDF算法实现
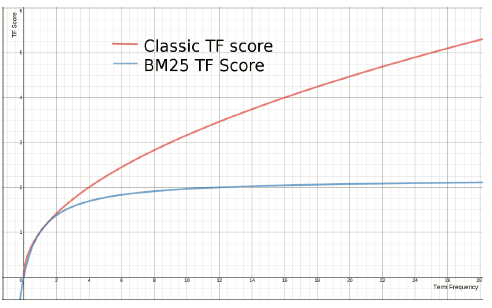
BM-25算法
和经典的TF-IDF相比,当TF无限增加时,BM 25算分会趋于一个数值.
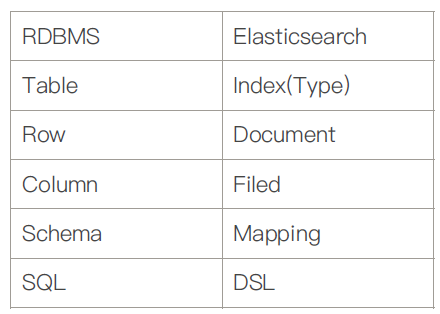
文档 ElasticSearch 是面向文档的,是文档所有可搜索数据的最小单元,文档会被序列化保存到JSON当中,每个文档都有一个UniqueID.
元数据 _index 文档存储的逻辑地方,实际存储的位置在每个分片当中(相当于db).
索引 索引是文档的容器,是一类文档的结合
Index提现了逻辑空间的概念,每个索引都有自己定义的Mapping(用于定义包含文档的字段名和类型名)
Shard提现了物理空间的概念(索引中的数据分散到Shard上)
索引的Mapping与Settings的区别 Mapping定义索引当中的文档字段类型,而Setting定义的是不同数据的分布
ES与传统关系型数据库的比较
分布式特性 ES实现了存储的水平扩展,以及选举机制等.
Master Node 与 Master-eligble Node Master的节点选举是由Master-eligble Node选举完成,当第一个节点启动时会将自己选为Msater节点.
集群的状态信息保存在Master节点,并且只有Master才能修改:
所有节点信息
所有的索引和其它相关的Mapping与Setting信息
分片的路由信息
DataNode与Coordinating Node 可以保存数据的节点叫做DataNode
Coordinating Node 负责接收Client请求,将请求发送到合适的节点,最终把结果汇集到一起
分片 主分片,用以解决数据水平扩展的问题.通过主分片可以将数据分不到集群的不同节点上
一个分片是一个运行的Lucene的实例
主分片在创建索引时指定,不允许修改
副本,用于解决高可用的问题
副本分片数可以动态调整
增加副本数提高服务读取的吞吐性能
注意分片数的设置 如果设置的过小导致后续无法水平扩展以及单个分片数据量过大.如果分片数设置过大影响相关性打分,影响统计结果的准确性,并且单个节点上过多的分片会导致资源浪费.
CRUD
Index操作:如果ID存在先删除文档,再创建文档,会增加版本号.如果ID不存在创建新的文档.
Create操作:如果ID存在,直接失败
Update操作:文档必须存在,更新只会对相应的字段.更新的内容需要置于doc字段中.
批量操作 _bulk 为了提升性能,支持一次调用多个操作,单条操作失败不会影响其他操作,返回结果包含每一条操作执行的结果.
1 2 3 4 5 6 POST /_bulk { "delete": { "_index": "log", "_type": "mylog", "_id": "123" }} { "create": { "_index": "log", "_type": "mylog", "_id": "123" }} { "title": "123" } { "index": { "_index": "website", "_type": "blog" }} { "title": "456t" }
_mget 批量读取
1 2 3 4 5 GET /test/_mget { "docs" : [ { "_id" : "1"}, {"_id" : "2"}] }
_msearch 1 2 3 4 5 6 POST kibana_sample_data_ecommerce/_msearch {} {"query" : {"match_all" : {}},"size":1} {"index" : "kibana_sample_data_flights"} {"query" : {"match_all" : {}},"size":2}
Analyzer 全文本转换为单词这一过程称为分词,分词通过Analyzer实现的.
Analyzer 组成 Character Filters:针对原始文本的处理,例如去除转义符
Tip:ES内置了许多的分词器,可以直接使用或者安装plugin下载对应的分词器
QueryDSL 查询搜索示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 POST /movies, 404 _idx/_search?ignore_unavailable=true { "profile" : true , "query" : { "match_all" : { } } } POST /kibana_sample_data_ecommerce/_search { "from" : 10 , "size" : 20 , "query" : { "match_all" : { } } } #对日期排序 POST kibana_sample_data_ecommerce/_search { "sort" : [ { "order_date" : "desc" } ] , "query" : { "match_all" : { } } } #source filtering POST kibana_sample_data_ecommerce/_search { "_source" : [ "order_date" ] , "query" : { "match_all" : { } } } #脚本字段 GET kibana_sample_data_ecommerce/_search { "script_fields" : { "new_field" : { "script" : { "lang" : "painless" , "source" : "doc['order_date'].value+'hello'" } } } , "query" : { "match_all" : { } } } POST movies/_search { "query" : { "match" : { "title" : "last christmas" } } } POST movies/_search { "query" : { "match" : { "title" : { "query" : "last christmas" , "operator" : "and" } } } } POST movies/_search { "query" : { "match_phrase" : { "title" : { "query" : "one love" } } } } POST movies/_search { "query" : { "match_phrase" : { "title" : { "query" : "one love" , "slop" : 1 } } } }
基于Term的查询 Term 是表达语意的最小单位.对输入不不做分词 。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分.
可以通过Constant Score 将查询转换成一个Filtering,避免算分,并利用缓存,提高性能.
Term查询 :Term Query / Range Query / Exists Query / Prefix Query /Wildcard Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 POST /products/_bulk { "index" : { "_id" : 1 } } { "productID" : "XHDK-A-1293-#fJ3" , "desc" : "iPhone" } { "index" : { "_id" : 2 } } { "productID" : "KDKE-B-9947-#kL5" , "desc" : "iPad" } { "index" : { "_id" : 3 } } { "productID" : "JODL-X-1937-#pV7" , "desc" : "MBP" } POST /products/_search { "query" : { "term" : { "desc" : { "value" : "iPhone" } } } } POST /products/_search { "explain" : true , "query" : { "constant_score" : { "filter" : { "term" : { "productID.keyword" : "XHDK-A-1293-#fJ3" } } } } }
基于全文本的查询 全文本的查询: Match Query / Match Phrase Query / Query String Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 POST groups/_doc { "names" : [ "John Water" , "Water Smith" ] } POST groups/_search { "query" : { "match_phrase" : { "names" : { "query" : "Water Water" , "slop" : 100 } } } } POST groups/_search { "query" : { "match_phrase" : { "names" : "Water Smith" } } }
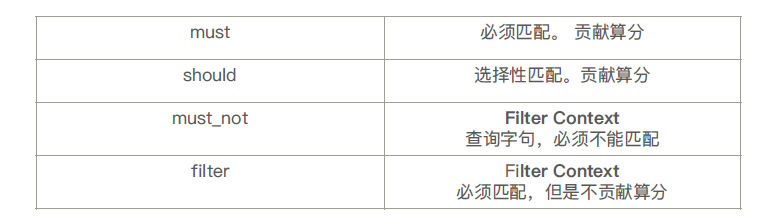
Bool查询 Bool查询是一个或者多个查询子句的组合.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST _search { "query" : { "bool" : { "filter" : { "term" : { "avaliable" : "true" } } , "must_not" : { "range" : { "price" : { "lte" : 10 } } } } } }
同一层级下的竞争字段,具有有相同的权重.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 POST /animals/_search { "query" : { "bool" : { "should" : [ { "term" : { "text" : "brown" } } , { "term" : { "text" : "red" } } , { "term" : { "text" : "quick" } } , { "term" : { "text" : "dog" } } ] } } } POST /animals/_search { "query" : { "bool" : { "should" : [ { "term" : { "text" : "quick" } } , { "term" : { "text" : "dog" } } , { "bool" : { "should" : [ { "term" : { "text" : "brown" } } , { "term" : { "text" : "brown" } } ] } } ] } } }
Disjunction Max Query 由于Bool多字段should查询时,多个要查询内容存在竞争关系,因此在算分规则上是叠加的,而不是寻找最匹配的.最匹配的评分 作为最终评分返回.
1 2 3 4 5 6 7 8 9 10 11 12 POST blogs/_search { "query" : { "dis_max" : { "queries" : [ { "match" : { "title" : "Quick pets" } } , { "match" : { "body" : "Quick pets" } } ] , "tie_breaker" : 0.2 } } }
算分流程
获得最佳匹配语句的评分_score 。
将其他匹配语句的评分与tie_breaker 相乘
对以上评分求和并规范化
Multi-Math 多字段匹配 支持三种类型:
最佳字段(Best Fields)
多数字段(Most Fields)
混合字段(Cross Field)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 POST blogs/_search { "query" : { "dis_max" : { "queries" : [ { "match" : { "title" : "Quick pets" } } , { "match" : { "body" : "Quick pets" } } ] , "tie_breaker" : 0.2 } } } POST blogs/_search { "query" : { "multi_match" : { "type" : "best_fields" , "query" : "Quick pets" , "fields" : [ "title" , "body" ] , "tie_breaker" : 0.2 , "minimum_should_match" : "20%" } } } PUT /titles { "mappings" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "english" , "fields" : { "std" : { "type" : "text" , "analyzer" : "standard" } } } } } } POST titles/_bulk { "index" : { "_id" : 1 } } { "title" : "My dog barks" } { "index" : { "_id" : 2 } } { "title" : "I see a lot of barking dogs on the road " } GET /titles/_search { "query" : { "multi_match" : { "query" : "barking dogs" , "type" : "most_fields" , "fields" : [ "title^10" , "title.std" ] } } }
高亮显示 通过Highlight字段指定要高亮显示的标签.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 POST tmdb/_search { "_source" : [ "title" , "overview" ] , "query" : { "multi_match" : { "query" : "basketball with cartoon aliens" , "fields" : [ "title" , "overview" ] } } , "highlight" : { "fields" : { "overview" : { "pre_tags" : [ "\\033[0;32;40m" ] , "post_tags" : [ "\\033[0m" ] } , "title" : { "pre_tags" : [ "\\033[0;32;40m" ] , "post_tags" : [ "\\033[0m" ] } } } }
Search Template & Index Template ES中支持脚本运行一些查询,这里就用到了SearchTempplate.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 POST _scripts/tmdb { "script" : { "lang" : "mustache" , "source" : { "_source" : [ "title" , "overview" ] , "size" : 20 , "query" : { "multi_match" : { "query" : "{{q}}" , "fields" : [ "title" , "overview" ] } } } } } POST tmdb/_search/template { "id" : "tmdb" , "params" : { "q" : "basketball with cartoon aliens" } }
Mapping & Dynamic Mapping Mapping 类似于数据库中的scheme,用于定义索引中的字段名,定义字段类型等.
数据类型 简单类型:
Text/Keyword
Date
Interger/Float
Boolean
IPV4&IPV6
Keyword和Text区别是 Keyword在被索引时不需要做特殊的处理,而Text需要分词特殊处理.
复杂类型:
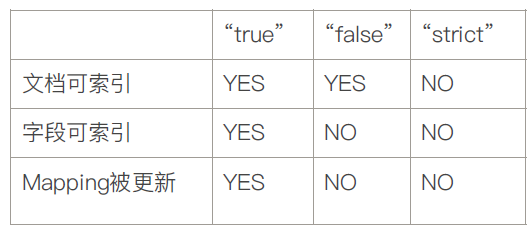
Dynamic Mapping 在写入文档的时候如果文档不存在,那么ES帮我自动生成一套Mapping.
Dynamic为true字段可以被索引,Mapping也同时被更新.
对已有字段数据写入,就不在支持修改字段的定义,Lucene实现的倒排索引,一旦生成后就不允许修改.如果希望字段改变,必须Reindex,重建索引.
设置Mapping 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 PUT users { "mappings" : { "properties" : { "firstName" : { "type" : "text" } , "lastName" : { "type" : "text" , "null_value" : "NULL" , 当该字段为NULL, 只有keyword支持NULL值设定 } , "mobile" : { "type" : "text" , ' "index" : false } } } }
多字段类型 在索引文档的时候,可以对单个字段指定额外的字段类型,比如你可以对text字段指定一个keyword类型,这样这个字段就可以用于排序等操作了,也可以为字段指定不同的分词器.
1 2 3 4 5 6 7 8 9 10 11 12 13 PUT my_index{ "mappings" : { "properties" : { "city" : { "type" : "text" , "fields" : { "raw" : { "type" : "keyword" } } } } } }
Index alias 可以帮助我们实现零停机运维.
1 2 3 4 5 6 7 8 9 10 11 POST _aliases { "actions" : [ { "add" : { "index" : "movies-2019" , "alias" : "movies-latest" } } ] }
算分控制 控制相关性算分 使用Boost,更改语句结构等都可能对算分造成影响.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 POST testscore/_search { "query" : { "boosting" : { "positive" : { "term" : { "content" : "elasticsearch" } } , "negative" : { "term" : { "content" : "like" } } , "negative_boost" : 0.2 } } }
Function Score Query Function Score Query: 可以在查询结束后,对每一个匹配的文档进行一系列的重新算分,根据新生成的分数进行排序。
提供了几种默认的计算分值的函数
Weight :为每一个文档设置一个简单而不被规范化的权重(权重与算分直接相乘得出新的算分)
Field Value Factor:使用该数值来修改_score,例如将“热度”和“点赞数”作为算分的参考因素(指定字段的值与算分相乘得出新的算分)
Random Score:为每一个用户使用一个不同的随机算分结果
衰减函数: 以某个字段的值为标准,距离某个值越近,得分越高
Script Score:自定义脚本完全控制所需逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 PUT /blogs/_doc/3 { "title" : "About popularity" , "content" : "In this post we will talk about..." , "votes" : 1000000 } POST /blogs/_search { "query" : { "function_score" : { "query" : { "multi_match" : { "query" : "popularity" , "fields" : [ "title" , "content" ] } } , "field_value_factor" : { "field" : "votes" } } }
排序 Elasticsearch 默认采用相关性算分对结果进行降序排序
什么情况下可以排序 排序是针对字段原始内容进行的。倒排索引无法发挥作用.需用到正排索引。通过文档Id 和字段快速得到字段原始内容.
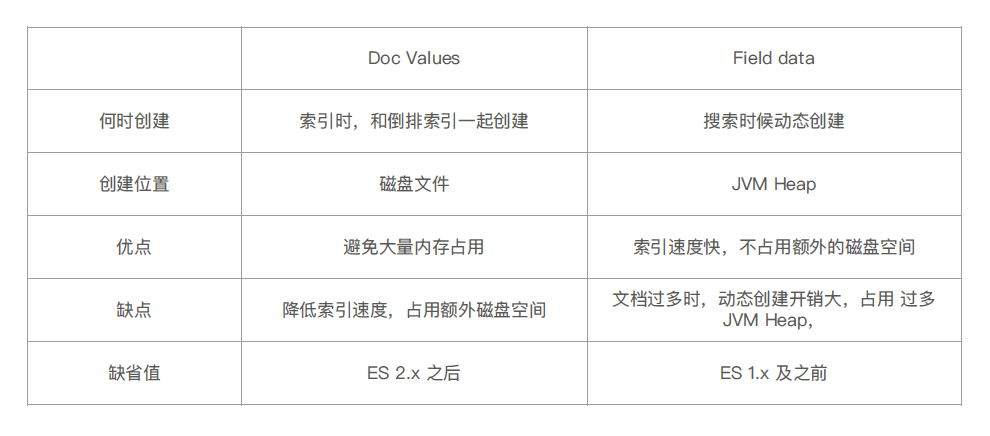
Fielddata与Doc Values (列式存储,对Text 类型无效)就可以排序
Field Data · 默认关闭,可以通过Mapping 设置打开。修改设置后,即时生效,无需重建索引
其他字段类型不支持,只支持对Text 进行设定
打开后,可以对Text 字段进行排序。但是对分词后的term 排序,所以,结果往往无法满足预期,不建议使用
部分情况下打开,满足一些聚合分析的特定需求
Suggester Api Term suggester 每个建议都包含了了一个算分,相似性是通过Levenshtein Edit Distance 的算法实现的。核心思想就是一个词改动多少字符就可以和另外一个词一致。提供了很多可选参数来控制相似性的模糊程度。例如"max_edits".
三种模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 POST articles/_bulk { "index" : { } } { "body" : "lucene is very cool" } { "index" : { } } { "body" : "Elasticsearch builds on top of lucene" } { "index" : { } } { "body" : "Elasticsearch rocks" } { "index" : { } } { "body" : "elastic is the company behind ELK stack" } { "index" : { } } { "body" : "Elk stack rocks" } { "index" : { } } { "body" : "elasticsearch is rock solid" } POST /articles/_search { "size" : 1 , "query" : { "match" : { "body" : "lucen rock" } } , "suggest" : { "term-suggestion" : { "text" : "lucen rock" , "term" : { "suggest_mode" : "missing" , "field" : "body" } } } } { "took" : 104 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 1 , "relation" : "eq" } , "max_score" : 1.5904956 , "hits" : [ { "_index" : "articles" , "_type" : "_doc" , "_id" : "kmrdFXEBdPgFvjK8qrgk" , "_score" : 1.5904956 , "_source" : { "body" : "elasticsearch is rock solid" } } ] } , "suggest" : { "term-suggestion" : [ { "text" : "lucen" , "offset" : 0 , "length" : 5 , "options" : [ { "text" : "lucene" , "score" : 0.8 , "freq" : 2 } ] } , { "text" : "rock" , "offset" : 6 , "length" : 4 , "options" : [ ] } ] } }
Phrase Suggester Phrase Suggester 在Term Suggester 上增加了一些额外的逻辑
这里不再赘述,如想详细了解请查看相关文档.
Completion Suggester ES很方便的为我们提供了补全功能,而且性能很好是基于内存操作的.FST只能支持前缀索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 PUT articles { "mappings" : { "properties" : { "title_completion" : { "type" : "completion" } } } } POST articles/_bulk { "index" : { } } { "title_completion" : "lucene is very cool" } { "index" : { } } { "title_completion" : "Elasticsearch builds on top of lucene" } { "index" : { } } { "title_completion" : "Elasticsearch rocks" } { "index" : { } } { "title_completion" : "elastic is the company behind ELK stack" } { "index" : { } } { "title_completion" : "Elk stack rocks" } { "index" : { } } POST articles/_search?pretty { "size" : 0 , "suggest" : { "article-suggester" : { "prefix" : "el " , "completion" : { "field" : "title_completion" } } } } { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 0 , "relation" : "eq" } , "max_score" : null , "hits" : [ ] } , "suggest" : { "article-suggester" : [ { "text" : "elk" , "offset" : 0 , "length" : 3 , "options" : [ { "text" : "Elk stack rocks" , "_index" : "articles" , "_type" : "_doc" , "_id" : "hmqXFHEBdPgFvjK8s7h-" , "_score" : 1.0 , "_source" : { "title_completion" : "Elk stack rocks" } } ] } ] } }
Context Suggester 我们有时候需要基于上下文生成对应的补全信息,比如在电影频道我们输入star 需要的补全信息和在美食频道输入的star补全信息就不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 PUT comments PUT comments/_mapping { "properties" : { "comment_autocomplete" : { "type" : "completion" , "contexts" : [ { "type" : "category" , "name" : "comment_category" } ] } } } POST comments/_doc { "comment" : "I love the star war movies" , "comment_autocomplete" : { "input" : [ "star wars" ] , "contexts" : { "comment_category" : "movies" } } } POST comments/_doc { "comment" : "Where can I find a Starbucks" , "comment_autocomplete" : { "input" : [ "starbucks" ] , "contexts" : { "comment_category" : "coffee" } } } POST comments/_search { "suggest" : { "MY_SUGGESTION" : { "prefix" : "sta" , "completion" : { "field" : "comment_autocomplete" , "contexts" : { "comment_category" : "movies" } } } } } { "took" : 2 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 0 , "relation" : "eq" } , "max_score" : null , "hits" : [ ] } , "suggest" : { "MY_SUGGESTION" : [ { "text" : "sta" , "offset" : 0 , "length" : 3 , "options" : [ { "text" : "star wars" , "_index" : "comments" , "_type" : "_doc" , "_id" : "k2okFnEBdPgFvjK8argZ" , "_score" : 1.0 , "_source" : { "comment" : "I love the star war movies" , "comment_autocomplete" : { "input" : [ "star wars" ] , "contexts" : { "comment_category" : "movies" } } } , "contexts" : { "comment_category" : [ "movies" ] } } ] } ] } }
跨集群搜索 单集群问题:
当水平扩展时,节点数不能无限增加
当集群的meta 信息(节点,索引,集群状态)过多,会导致更更新压力变大,单个Active Master 会成为性能瓶颈,导致整个集群无法正常工作
跨集群搜索
允许任何节点扮演federated 节点,以轻量的方式,将搜索请求进行代理.
当集群无法水平扩展,或者需要将不同的集群数据实现数据的Federation,可以采用跨集群搜索(CCS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 bin/elasticsearch -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300 bin/elasticsearch -E node.name=cluster1node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301 bin/elasticsearch -E node.name=cluster2node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302 PUT _cluster/settings { "persistent" : { "cluster" : { "remote" : { "cluster0" : { "seeds" : [ "127.0.0.1:9300" ] , "transport.ping_schedule" : "30s" } , "cluster1" : { "seeds" : [ "127.0.0.1:9301" ] , "transport.compress" : true , "skip_unavailable" : true } , "cluster2" : { "seeds" : [ "127.0.0.1:9302" ] } } } } } #cURL curl -XPUT "http://localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d' { "persistent" : { "cluster" : { "remote" : { "cluster0" : { "seeds" : [ "127.0.0.1:9300" ] , "transport.ping_schedule" : "30s" } , "cluster1" : { "seeds" : [ "127.0.0.1:9301" ] , "transport.compress" : true , "skip_unavailable" : true } , "cluster2" : { "seeds" : [ "127.0.0.1:9302" ] } } } } } 'curl -XPUT "http://localhost:9201/_cluster/settings" -H 'Content-Type: application/json' -d' { "persistent" : { "cluster" : { "remote" : { "cluster0" : { "seeds" : [ "127.0.0.1:9300" ] , "transport.ping_schedule" : "30s" } , "cluster1" : { "seeds" : [ "127.0.0.1:9301" ] , "transport.compress" : true , "skip_unavailable" : true } , "cluster2" : { "seeds" : [ "127.0.0.1:9302" ] } } } } } 'curl -XPUT "http://localhost:9202/_cluster/settings" -H 'Content-Type: application/json' -d' { "persistent" : { "cluster" : { "remote" : { "cluster0" : { "seeds" : [ "127.0.0.1:9300" ] , "transport.ping_schedule" : "30s" } , "cluster1" : { "seeds" : [ "127.0.0.1:9301" ] , "transport.compress" : true , "skip_unavailable" : true } , "cluster2" : { "seeds" : [ "127.
分布式特性 ES天生支持分布式
分片 Primary Shard,可以将一份索引的数据,分散在多个Data Node 上,实现存储的水平扩展
通过引入副本分片(Replica Shard)
分片数的设定 主分片数过小:如果该索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展
文档到分片的路由 shard = hash(_routing) % number_of_primary_shards
分片内部原理 ES 中最小的工作单元 是一个Lucene 的Index.
倒排索引采用Immutable Design:
无需考虑并发写文件的问题,避免了了锁机制带来的性能问题
一旦读入内核的文件系统缓存,便留在缓存里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能.
缓存容易生成和维护/ 数据可以被压缩
缺点:
如果需要让一个新的文档可以被搜索,需要重建整个索引
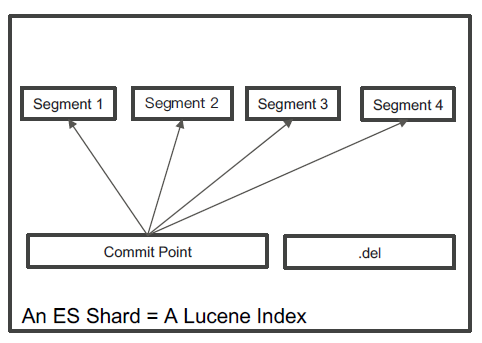
在Lucene 中,单个倒排索引文件被称为Segment。Segment 是自包含的,不可变更的。多个Segments 汇总在一起,称为Lucene 的Index,其对应的就是ES 中的Shard.
删除的文档信息,保存在“.del”文件中.
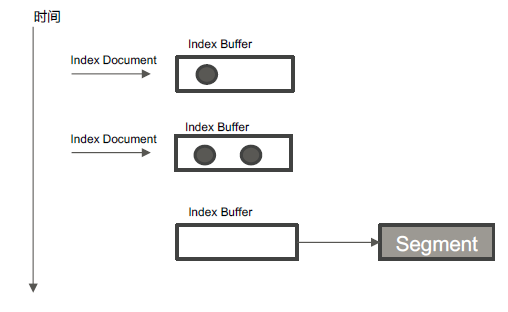
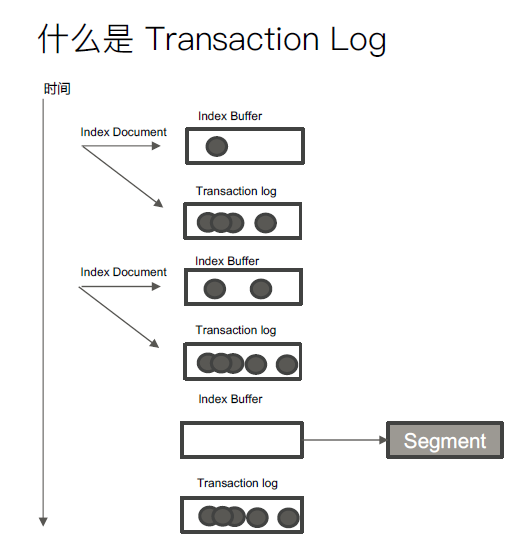
Refresh机制
将Index buffer 写入Segment 的过程叫Refresh。Refresh 不执行fsync 操作.
Refresh 频率:默认1 秒发生一次,可通过index.refresh_interval 配置。Refresh 后,数据就可以被搜索到了。这也是为什么Elasticsearch 被称为近实时搜索
如果系统有大量的数据写入,那就会产生很多的Segment
Index Buffer 被占满时,会触发Refresh,默认值是JVM 的10%
TransactionLog机制
Segment 写磁盘的过程相对耗时,借助文件系统缓存,Refresh 时,先将Segment 写入缓存以开放查询
为了保证数据不会丢失。所以在Index 文档时,同时写Transaction Log,高版本开始,Transaction Log 默认落盘。每个分片有一个Transaction Log
在ES Refresh 时,Index Buffer 被清空,Transaction log 不不会清空
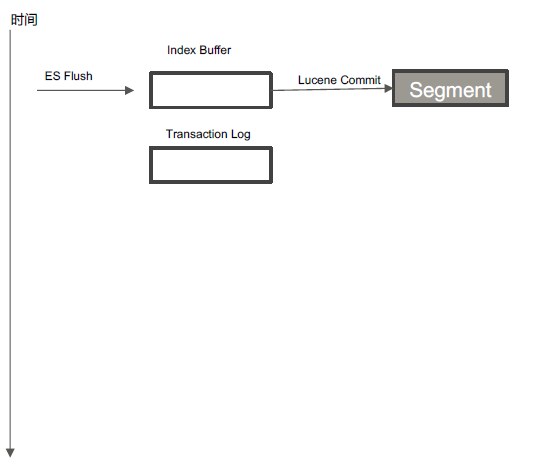
Flush机制
调用Refresh,Index Buffer 清空并且Refresh
调用fsync,将缓存中的Segments写入磁盘
清空(删除)Transaction Log
默认30 分钟调用一次
Transaction Log 满(默认512 MB)
Merge机制 Segment 很多,需要被定期被合并,减少Segments / 删除已经删除的文档.POST my_index/_forcemerge手动操作.
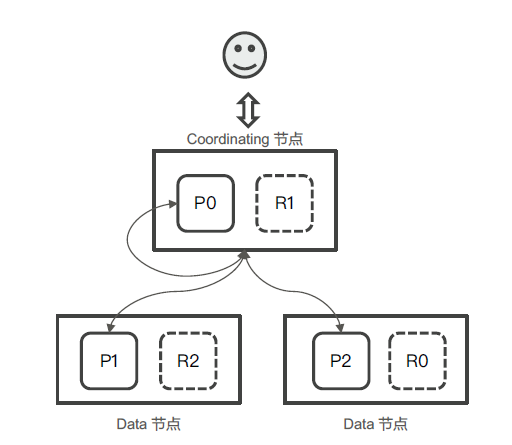
分布式查询 1.Query阶段
用户发出搜索请求到ES 节点。节点收到请求后, 会以Coordinating 节点的身份,在6 个主副分片中随机选择3 个分片,发送查询请求
被选中的分片执行查询,进行排序。然后,每个分片都会返回From + Size 个排序后的文档Id 和排序值给Coordinating 节点
2.Fetch 阶段
Coordinating Node 会将Query 阶段,从从每个分片获取的排序后的文档Id 列表,重新进行排序。选取From 到From + Size个文档的Id
以multi get 请求的方式,到相应的分片获取详细的文档数据
QueryThenFetch问题:
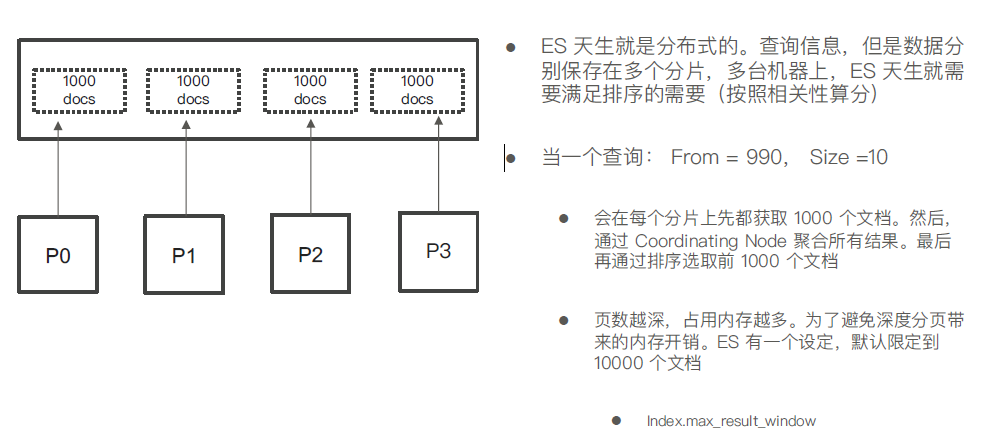
1.性能问题,深度分页
解决:
分页 传统的分页方式会有深度分页的问题,页数越多性能极差
Tip:传统分页查询请见QueryDSL一节
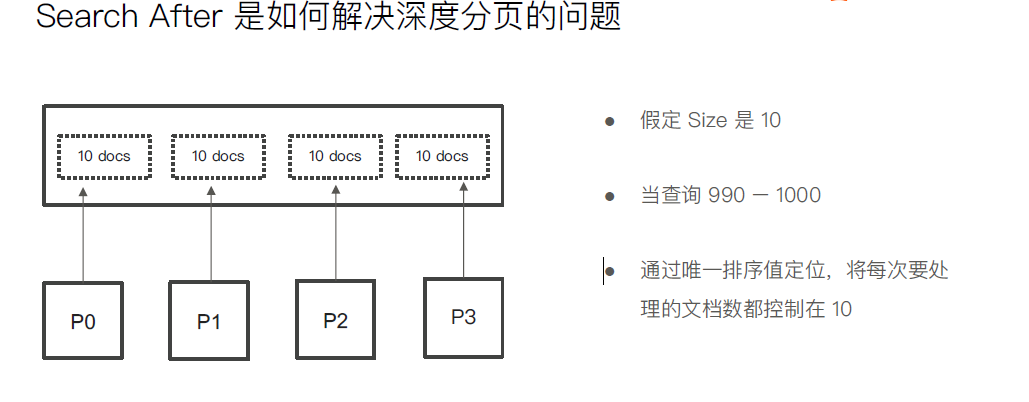
Search After
· 避免深度分页的性能问题,可以实时获取下一页文档信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 POST tmdb/_search { "from" : 10000 , "size" : 1 , "query" : { "match_all" : { } } } #Scroll API DELETE users POST users/_doc { "name" : "user1" , "age" : 10 } POST users/_doc { "name" : "user2" , "age" : 11 } POST users/_doc { "name" : "user2" , "age" : 12 } POST users/_doc { "name" : "user2" , "age" : 13 } POST users/_count POST users/_search { "size" : 1 , "query" : { "match_all" : { } } , "sort" : [ { "age" : "desc" } , { "_id" : "asc" } ] } POST users/_search { "size" : 1 , "query" : { "match_all" : { } } , "search_after" : [ 10 , "ZQ0vYGsBrR8X3IP75QqX" ] , "sort" : [ { "age" : "desc" } , { "_id" : "asc" } ] }
Scroll Api · 创建一个快照,有新的数据写入以后,无法被查到
需要全部文档,例例如导出全部数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 DELETE users POST users/_doc { "name" : "user1" , "age" : 10 } POST users/_doc { "name" : "user2" , "age" : 20 } POST users/_doc { "name" : "user3" , "age" : 30 } POST users/_doc { "name" : "user4" , "age" : 40 } POST /users/_search?scroll=5 m { "size" : 1 , "query" : { "match_all" : { } } } POST users/_doc { "name" : "user5" , "age" : 50 } POST /_search/scroll { "scroll" : "1m" , "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAWAWbWdoQXR2d3ZUd2kzSThwVTh4bVE0QQ==" }
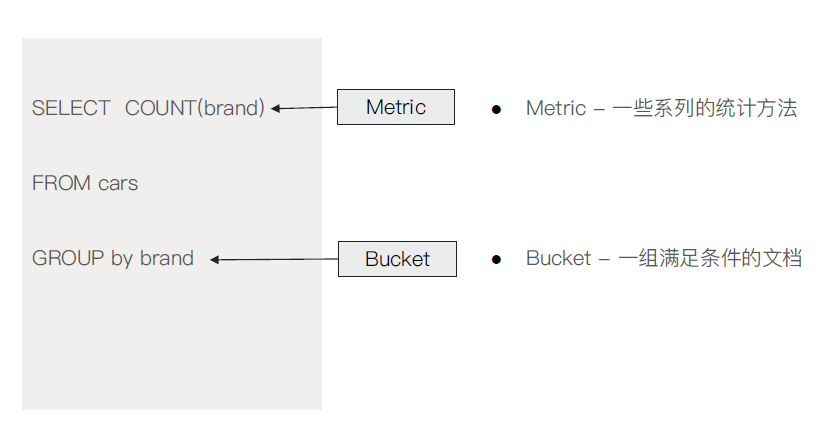
Bucket Aggregation & Metric Aggregation ES 聚合分析的默认作用范围是query 的查询结果集。
直观理解
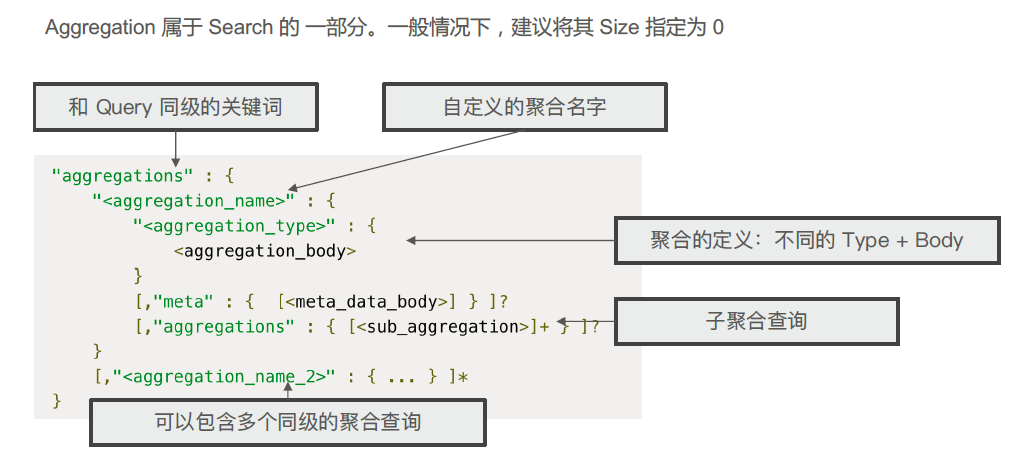
使用方式
补充:HAVING ON 字句, 相当于以下方式改变聚合的作用范围
· Filter
· Post_Filter
· Global
Metric Aggregation ·单值分析:只输出一个分析结果
○ min, max, avg, sum
○ Cardinality (类似distinct Count)
· 多值分析:输出多个分析结果
○ stats, extended stats
○ percentile, percentile rank
○ top hits (排在前面的示例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 PUT /employees/ { "mappings" : { "properties" : { "age" : { "type" : "integer" } , "gender" : { "type" : "keyword" } , "job" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 50 } } } , "name" : { "type" : "keyword" } , "salary" : { "type" : "integer" } } } } POST employees/_search { "size" : 0 , "aggs" : { "max_salary" : { "max" : { "field" : "salary" } } , "min_salary" : { "min" : { "field" : "salary" } } , "avg_salary" : { "avg" : { "field" : "salary" } } } }
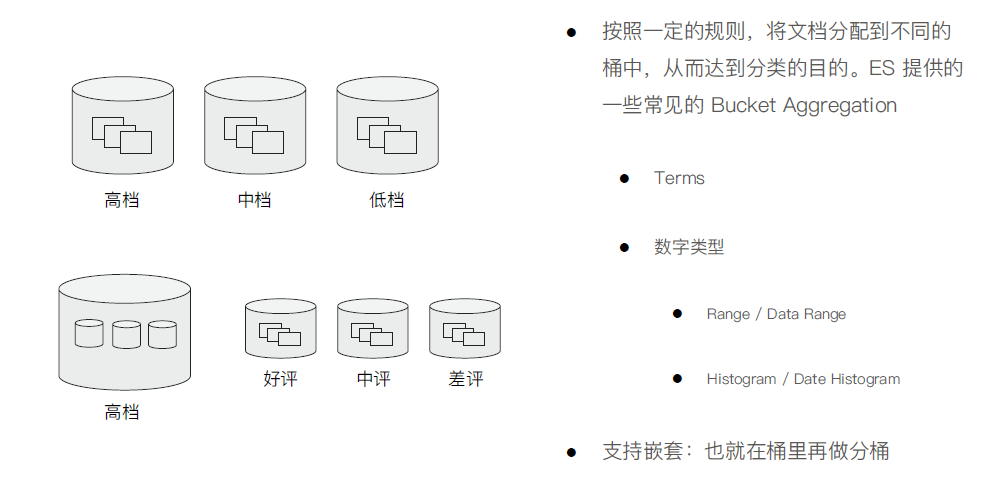
Bucket Aggregation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 POST employees/_search { "size" : 0 , "aggs" : { "gender" : { "terms" : { "field" : "gender" } } } } #指定 bucket 的 size POST employees/_search { "size" : 0 , "aggs" : { "ages_5" : { "terms" : { "field" : "age" , "size" : 3 } } } } POST employees/_search { "size" : 0 , "aggs" : { "gender" : { "terms" : { "field" : "gender" } } } } # 指定size,不同工种中,年纪最大的3 个员工的具体信息 POST employees/_search { "size" : 0 , "aggs" : { "jobs" : { "terms" : { "field" : "job.keyword" } , "aggs" : { "old_employee" : { "top_hits" : { "size" : 3 , "sort" : [ { "age" : { "order" : "desc" } } ] } } } } } } #Salary Ranges 分桶,可以自己定义 key POST employees/_search { "size" : 0 , "aggs" : { "salary_range" : { "range" : { "field" : "salary" , "ranges" : [ { "to" : 10000 } , { "from" : 10000 , "to" : 20000 } , { "key" : ">20000" , "from" : 20000 } ] } } } } #Salary Histogram, 工资0 到10 万,以 5000 一个区间进行分桶 POST employees/_search { "size" : 0 , "aggs" : { "salary_histrogram" : { "histogram" : { "field" : "salary" , "interval" : 5000 , "extended_bounds" : { "min" : 0 , "max" : 100000 } } } } } # 嵌套聚合1 ,按照工作类型分桶,并统计工资信息 POST employees/_search { "size" : 0 , "aggs" : { "Job_salary_stats" : { "terms" : { "field" : "job.keyword" } , "aggs" : { "salary" : { "stats" : { "field" : "salary" } } } } } } # 多次嵌套。根据工作类型分桶,然后按照性别分桶,计算工资的统计信息 POST employees/_search { "size" : 0 , "aggs" : { "Job_gender_stats" : { "terms" : { "field" : "job.keyword" } , "aggs" : { "gender_stats" : { "terms" : { "field" : "gender" } , "aggs" : { "salary_stats" : { "stats" : { "field" : "salary" } } } } } } } }
Term Aggregation 分词
· 字段需要打开fielddata,才能进行Terms Aggregation
· Keyword 默认支持doc_values
· Text 需要在Mapping 中enable。会按照分词后的结果进行分
在Terms Aggregation 的返回中有两个特殊的数值
○ doc_count_error_upper_bound : 被遗漏漏的term 分桶,包含的文档,有可能的最大值
○ sum_other_doc_count: 除了了返回结果bucket的terms 以外,其他terms 的文档总数(总
Term 聚合为什么会不准 · Terms 聚合分析不准的原因,数据分散在多个分片上, Coordinating Node 无法获取数据全貌
· 解决方案1:当数据量量不大时,设置PrimaryShard 为1;实现准确性
Range & Histogram · 按照数字的范围,进行分桶
· 在Range Aggregation 中,可以自定义Key
Update By Query 一般在以下几种情况时,我们需要重建索引
Update By Query:在现有索引上重建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 # 写入文档 PUT blogs/_doc/1 { "content" : "Hadoop is cool" , "keyword" : "hadoop" } # 查看 Mapping GET blogs/_mapping # 修改 Mapping,增加子字段,使用英文分词器 PUT blogs/_mapping { "properties" : { "content" : { "type" : "text" , "fields" : { "english" : { "type" : "text" , "analyzer" : "english" } } } } } # 写入文档 PUT blogs/_doc/2 { "content" : "Elasticsearch rocks" , "keyword" : "elasticsearch" } # 查询新写入文档 POST blogs/_search { "query" : { "match" : { "content.english" : "Elasticsearch" } } } # 查询 Mapping 变更前写入的文档 POST blogs/_search { "query" : { "match" : { "content.english" : "Hadoop" } } } # Update所有文档 POST blogs/_update_by_query { } # 查询之前写入的文档 POST blogs/_search { "query" : { "match" : { "content.english" : "Hadoop" } } } # 查询 GET blogs/_mapping PUT blogs/_mapping { "properties" : { "content" : { "type" : "text" , "fields" : { "english" : { "type" : "text" , "analyzer" : "english" } } } , "keyword" : { "type" : "keyword" } } }
Reindex 修改索引的主分片数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # 创建新的索引并且设定新的Mapping PUT blogs_fix/ { "mappings" : { "properties" : { "content" : { "type" : "text" , "fields" : { "english" : { "type" : "text" , "analyzer" : "english" } } } , "keyword" : { "type" : "keyword" } } } } # Reindx API POST _reindex { "source" : { "index" : "blogs" } , "dest" : { "index" : "blogs_fix" } }
实践建议 · Text
○ 用于全文本字段,⽂文本会被Analyzer 分词
○ 默认不支持聚合分析及排序。需要设置fielddata 为true
· Keyword
○用于id,枚举及不不需要分词的⽂文本。例例如电话号码,email地址,手机号码,邮政编码,性别等
○ 适用于Filter(精确匹配),Sorting 和Aggregations
· 设置多字段类型
· 默认会为文本类型设置成text,并且设置一个keyword 的子字段
· 在处理理人类语言时,通过增加“英文”,“拼音”和“标准”分词器器,提高搜索结构
结构化数据 · 数值类型
· 尽量选择贴近的类型。例如可以用byte,就不不要⽤用long
· 枚举类型
· 设置为keyword。即便是数字,也应该设置成keyword,获取更加好的性能
· 其他
· 日期/ 布尔/ 地理理信息
检索 · 如不需要检索,排序和聚合分析
· Enable 设置成false
· 如不不需要检索
· Index 设置成false
· 对需要检索的字段,可以通过如下配置,设定存储粒度
· Index_options / Norms :不需要归一化数据时,可以关闭
避免正则查询 正则,通配符查询,前缀查询属于Term 查询,但是性能不不够好, 特别是将通配符放在开头,会导致性能的灾难